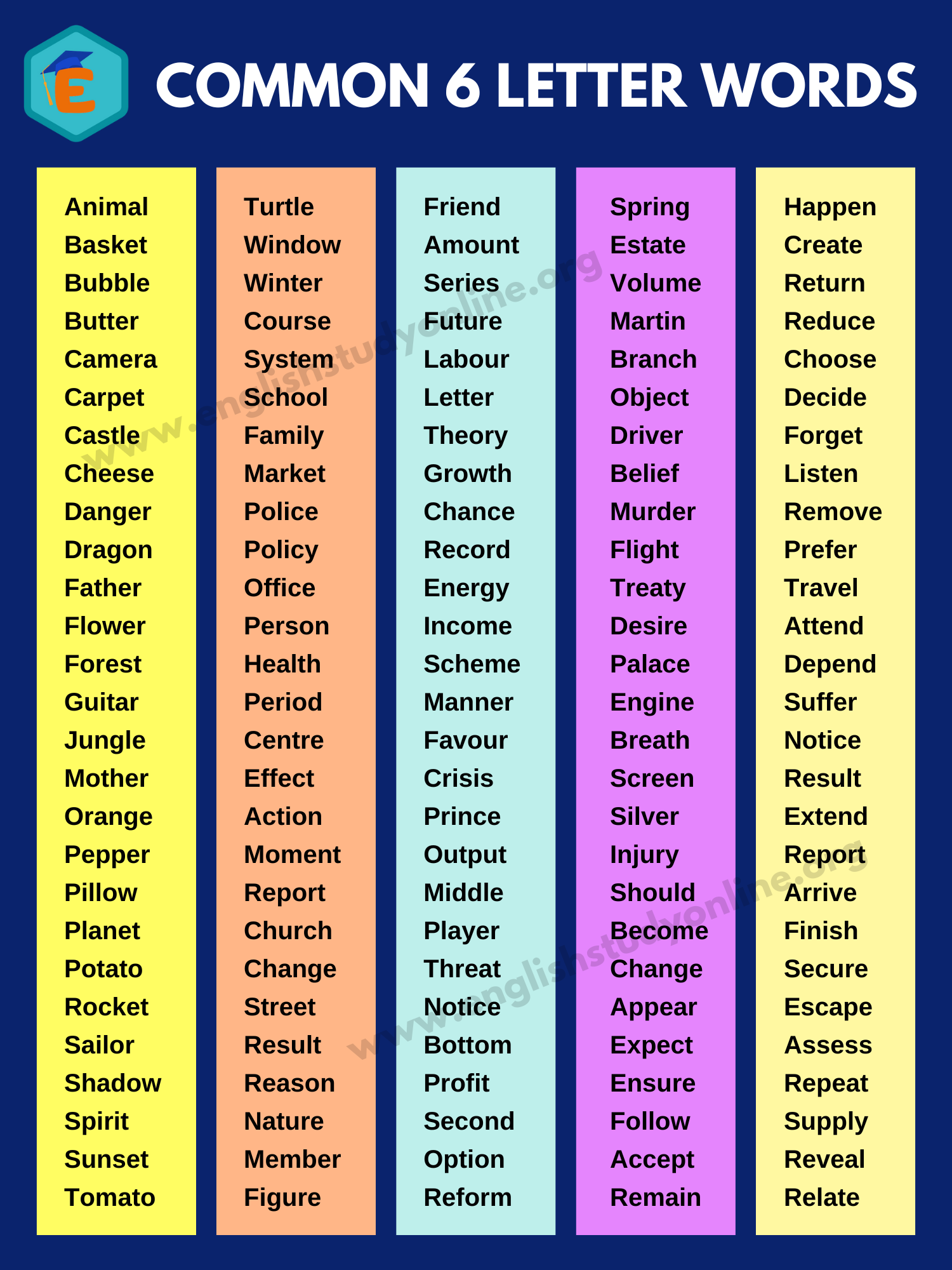
J'ai vu des dizaines de développeurs de jeux de lettres et de linguistes amateurs s'enfermer dans une pièce pendant des mois, convaincus que la clé du succès résidait dans une précision mathématique rigide. Un client est venu me voir l'an dernier après avoir investi 15 000 euros dans le développement d'une application de puzzles sémantiques. Son erreur ? Il avait bâti tout son moteur de jeu autour d'une contrainte arbitraire liée aux Words That Are 6 Letters sans comprendre la structure fréquentielle de la langue française. Résultat, ses utilisateurs se sont retrouvés face à des murs de répétitions ou, pire, à des termes tellement obscurs que l'engagement a chuté de 70 % en une semaine. Il n'avait pas réalisé que la longueur d'un mot n'est pas une catégorie esthétique, c'est une contrainte technique qui dicte la fluidité de l'interface et la charge cognitive du cerveau humain.
Croire que la longueur définit la difficulté est un piège
C'est l'erreur classique du débutant. On s'imagine qu'un mot de six lettres est intrinsèquement plus simple qu'un mot de dix, ou plus complexe qu'un mot de quatre. Dans les faits, la difficulté perçue ne dépend pas du nombre de caractères, mais de la structure phonotactique et de la fréquence d'usage. Si vous concevez un système pédagogique ou un jeu, ne tombez pas dans le panneau de la progression linéaire basée sur le comptage. Lisez plus sur un thème lié : cet article connexe.
Prenez le mot "OISEAU". Six lettres. Pourtant, pour un algorithme de reconnaissance ou un enfant en apprentissage, c'est un cauchemar à cause de l'accumulation de voyelles. À l'inverse, "STRING" (dans le sens informatique ou textile) est techniquement simple mais peut créer des biais contextuels. J'ai vu des projets entiers échouer parce que les concepteurs refusaient d'intégrer des variables de rareté. Ils piochaient dans une base de données de manière aléatoire en se disant "tant que ça fait six lettres, c'est bon". Non, ça ne l'est pas. Vous finissez par servir des termes comme "XYLÈNE" à des gens qui cherchent juste à s'amuser ou à apprendre les bases.
La solution consiste à pondérer chaque entrée selon l'échelle de fréquence Lexique3, une base de données du CNRS qui est la référence absolue en France. Si vous ne filtrez pas vos données par "fréquence de film" ou "fréquence de livre", votre base de données sera mathématiquement correcte mais humainement inutilisable. J'ai vu des applications de Scrabble en ligne perdre leurs utilisateurs les plus fidèles parce que le dictionnaire interne privilégiait des formes verbales archaïques de six lettres que personne n'a utilisées depuis le XIXe siècle. Les Échos a analysé ce crucial dossier de manière approfondie.
L'impact technique des Words That Are 6 Letters sur l'interface utilisateur
Le design ne s'arrête pas aux couleurs. Quand on travaille sur des interfaces mobiles, la gestion de l'espace est une science de la douleur. Beaucoup de concepteurs pensent que les Words That Are 6 Letters sont la solution miracle pour la symétrie. C'est une fausse sécurité. Sur un écran d'iPhone de génération standard, une grille de six colonnes impose une taille de police spécifique. Si vous ne prévoyez pas la gestion des glyphes larges comme le "M" ou le "W", votre design va exploser.
La gestion des glyphes et l'espacement
J'ai travaillé sur un projet où l'équipe de design avait tout testé avec le mot "ALIGNE". Tout était propre, les marges étaient parfaites. Mais une fois en production, quand l'utilisateur tombait sur "MAMMAIRE" ou "MAXIMA" (en version étendue), le texte débordait ou les boîtes de saisie devenaient illisibles. Vous devez concevoir pour le pire scénario de largeur de caractère, pas pour la moyenne.
L'erreur ici est de traiter le texte comme un bloc statique. Dans la langue française, la présence fréquente d'accents (é, è, ê, ë) modifie la hauteur de ligne. Si votre interface est verrouillée sur une hauteur de six lettres sans jambages inférieurs (comme "AVIONS"), elle sera ruinée dès qu'un "CYGNE" apparaîtra avec son "Y" et son "G" qui descendent sous la ligne de base. C'est ce genre de détails qui sépare un produit pro d'un projet étudiant qui va coûter une fortune en corrections de bugs CSS.
Ignorer la morphologie dérivationnelle du français
En anglais, on peut souvent s'en sortir avec des racines simples. En français, vouloir se limiter à des segments de six lettres vous force souvent à utiliser des formes conjuguées ou des pluriels qui gâchent l'expérience utilisateur. C'est là que le bât blesse : vous finissez par avoir une liste remplie de "MANGES", "CHANTE", "DANSES". C'est pauvre. C'est ennuyeux.
Comparaison : L'approche naïve vs l'approche experte
Imaginons que vous créez un outil de marketing par SMS où chaque caractère compte.
L'approche naïve : Vous forcez vos rédacteurs à utiliser des mots courts de manière systématique. Le message ressemble à ceci : "PROMO ! VENEZ VITE DANS NOS MAGS POUR VOIR NOS SOLDES." C'est haché, ça manque de professionnalisme et l'utilisateur a l'impression de recevoir un spam des années 2000. Vous avez respecté la contrainte de brièveté, mais vous avez tué la marque.
L'approche experte : On utilise la structure de la langue pour créer du rythme. Au lieu de forcer une longueur fixe, on choisit des termes qui évoquent l'action sans sacrifier la syntaxe. On utilise "OFFRES" (6 lettres) au lieu de "SOLDES" si le contexte de la marque est plus haut de gamme. On comprend que "VENEZ" est plus efficace que "ENTREZ" à cause de la force de l'impératif en français. On ne compte pas les lettres pour le plaisir de compter, on les compte pour optimiser la vitesse de lecture. L'approche experte utilise la psycholinguistique pour savoir que le cerveau traite "CADEAU" plus vite que "PRESENT" bien qu'ils fassent presque la même longueur, car le premier est plus iconique.
Le coût caché de la localisation et du dictionnaire
Si vous lancez un produit qui repose sur une structure de Words That Are 6 Letters, vous allez vous heurter violemment au mur de la traduction. Ce qui fonctionne en français avec six caractères demandera peut-être sept en espagnol ou huit en allemand. J'ai conseillé une entreprise de jeux de société qui voulait traduire un concept basé sur cette longueur fixe. Ils ont dû racheter tous leurs moules de fabrication parce que le marché allemand rendait le concept physiquement impossible à imprimer sur les tuiles de jeu.
Le coût d'un pivot de ce type après la production initiale se chiffre en dizaines de milliers d'euros. Si votre modèle d'affaires est lié à une contrainte de caractères, vous n'êtes pas en train de créer un produit global, vous créez une prison linguistique. La solution est de construire une architecture logicielle ou physique flexible dès le premier jour. On n'encode jamais la longueur "6" en dur dans le code. On utilise des variables de configuration que l'on peut ajuster par pays.
La fausse piste des algorithmes de génération automatique
Beaucoup pensent qu'il suffit de scraper le dictionnaire de l'Académie française et de filtrer par longueur pour obtenir une liste de travail. C'est la garantie d'obtenir une base de données remplie de termes que personne ne comprend. Le français est une langue vivante, pas une liste Excel.
J'ai vu des systèmes de sécurité basés sur des mots de passe de six lettres (ce qui est déjà une erreur de sécurité majeure en soi) qui suggéraient des mots comme "AIGUES" ou "OSTRAS". Personne ne sait écrire "OSTRAS" sans faire de faute. Résultat : le support client est inondé de demandes de réinitialisation parce que les utilisateurs ne retrouvent pas l'orthographe exacte de leur propre identifiant.
Pour éviter ça, vous devez utiliser des listes de "mots de base" (lemmatisation). Ne prenez que les infinitifs pour les verbes et les singuliers masculins pour les adjectifs, sauf si vous avez une raison pédagogique spécifique de faire autrement. Si vous laissez les algorithmes décider, ils choisiront toujours l'option la plus statistiquement probable selon leur base d'entraînement, ce qui n'est pas forcément l'option la plus utile pour un être humain.
Pourquoi votre base de données va vous trahir
La gestion des doublons et des homonymes est le dernier clou dans le cercueil des projets mal préparés. En français, "AVIONS" peut être un nom pluriel ou une forme du verbe avoir. Si votre système ne gère pas le contexte (le "Part-of-Speech tagging"), vous allez envoyer des messages ou créer des puzzles qui n'ont aucun sens.
J'ai corrigé un bug sur une plateforme d'apprentissage où le système demandait de traduire le mot "VOLANT". L'utilisateur écrivait la bonne réponse en anglais, mais le système comptait faux parce qu'il attendait la traduction du verbe "voler" au participe présent, alors que l'image montrait un volant de voiture. Cette erreur de contexte arrive systématiquement quand on se contente de filtrer par longueur sans attribuer de métadonnées sémantiques à chaque mot. Chaque entrée dans votre liste doit posséder au moins trois tags :
- Catégorie grammaticale.
- Niveau de difficulté (A1 à C2).
- Champ lexical.
Sans ces trois piliers, votre liste n'est qu'un bruit statistique sans valeur commerciale.
La vérification de la réalité
On va se dire les choses franchement. Si vous lisez ceci en pensant qu'il existe un secret magique pour manipuler les mots de six lettres et devenir le prochain succès de l'App Store ou du marketing viral, vous vous trompez de combat. La vérité, c'est que la longueur des mots n'intéresse personne à part les maniaques de l'Oulipo ou les développeurs de clones de Wordle.
Le succès ne vient pas de la contrainte, il vient de la manière dont vous cachez la contrainte pour servir l'expérience. Si l'utilisateur remarque que vous n'utilisez que des termes d'une certaine longueur, c'est que votre contenu est devenu prévisible et donc ennuyeux. J'ai passé des années à voir des projets mourir parce que les créateurs étaient amoureux de leur système technique au lieu d'être amoureux de l'usage qu'en faisaient les gens.
Travailler avec ces structures demande une rigueur chirurgicale sur la qualité des données. Si vous n'êtes pas prêt à passer des centaines d'heures à nettoyer manuellement vos listes, à vérifier chaque homonyme et à tester votre interface sur les écrans les plus petits du marché, laissez tomber. Le français est une langue trop riche et trop complexe pour être réduite à un simple compteur de caractères sans que cela ne se voie. Soyez pragmatique : utilisez la contrainte comme un guide, pas comme une loi absolue, sinon vous finirez par produire quelque chose de techniquement parfait mais de totalement inutile.