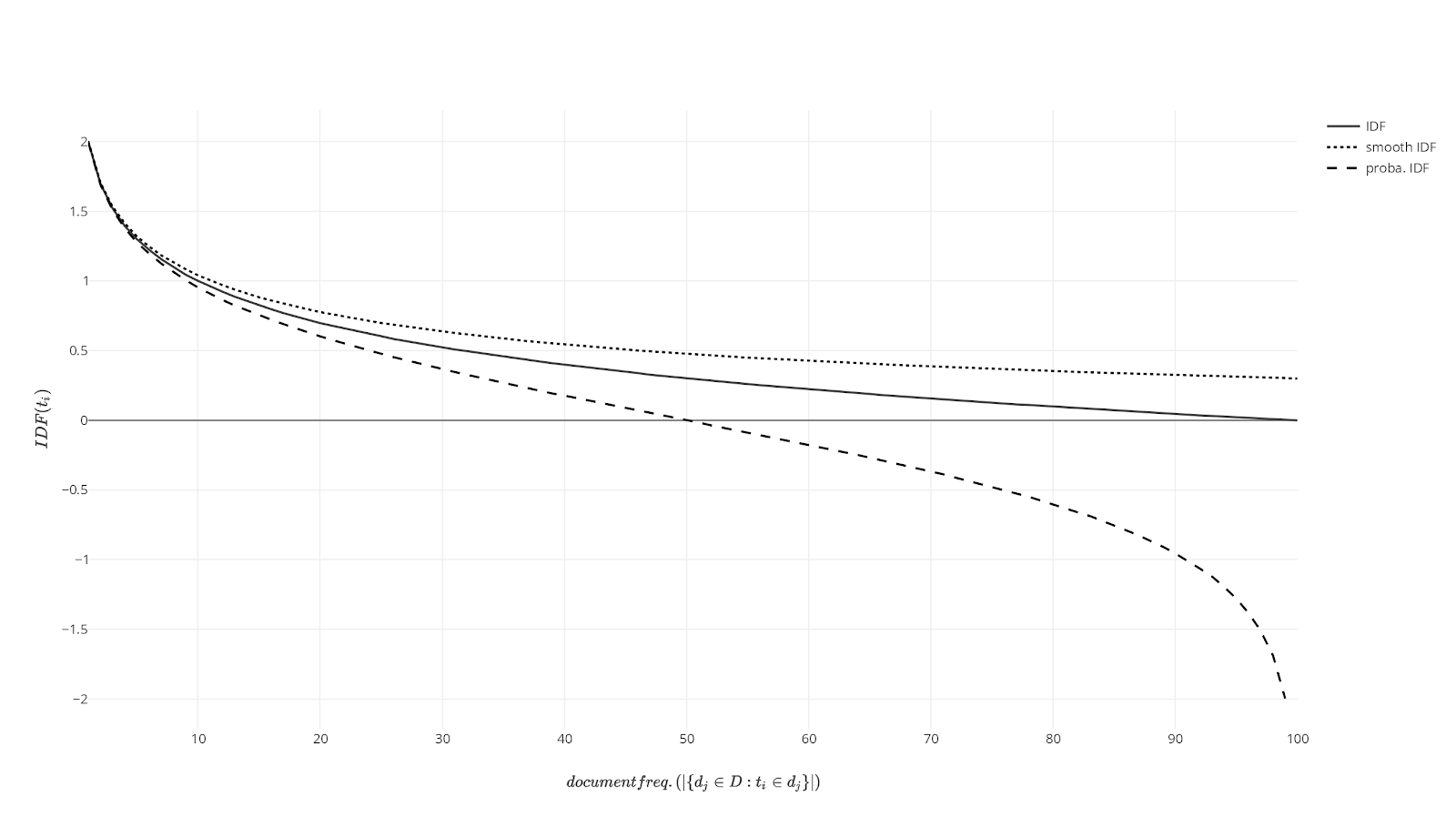
Les moteurs de recherche modernes et les systèmes d'archivage numérique continuent de s'appuyer sur la méthode Term Frequency Inverse Document Frequency pour classer la pertinence des contenus textuels. Créé initialement pour l'indexation bibliothécaire, ce calcul statistique permet d'évaluer l'importance d'un mot au sein d'un document par rapport à une collection complète de fichiers. Le Centre national de la recherche scientifique (CNRS) indique dans ses publications sur le traitement du langage naturel que cette technique demeure un pilier de l'informatique documentaire malgré l'émergence de l'intelligence artificielle générative.
La structure mathématique de ce système repose sur deux composantes distinctes qui s'équilibrent mutuellement. La première mesure la récurrence brute d'un terme dans un texte spécifique, tandis que la seconde pénalise les mots trop fréquents dans la langue générale, comme les articles ou les prépositions. Selon les travaux de Karen Spärck Jones, chercheuse à l'Université de Cambridge qui a théorisé ce concept dès 1972, cette approche garantit que les termes rares et porteurs de sens reçoivent un poids statistique plus élevé. Pour une plongée plus profonde dans ce domaine, nous recommandons : cet article connexe.
L'Application Industrielle de Term Frequency Inverse Document Frequency
Les entreprises de la Silicon Valley utilisent des variantes de ce protocole pour optimiser la rapidité de réponse de leurs serveurs. Le géant de la recherche Google a confirmé dans sa documentation technique que ses algorithmes originaux s'inspiraient directement de ces principes pour hiérarchiser les pages web. L'organisation interprofessionnelle de l'industrie logicielle estime que cette logique de pondération traite quotidiennement des milliards de requêtes à travers le monde.
La Mise en Oeuvre dans les Bibliothèques Numériques
La Bibliothèque nationale de France emploie des technologies similaires pour faciliter la navigation dans ses archives numérisées. Ce dispositif permet aux chercheurs de localiser des occurrences précises au sein de millions de pages de journaux historiques sans nécessiter une lecture manuelle exhaustive. Les ingénieurs système de l'institution expliquent que l'automatisation du tri textuel réduit les temps de recherche de près de 80 pour cent par rapport aux anciennes méthodes d'indexation. Pour obtenir des détails sur cette question, une couverture complète est disponible sur Journal du Net.
Le secteur juridique adopte également ce mécanisme pour la gestion des preuves électroniques lors des procédures de découverte. Les cabinets d'avocats internationaux s'appuient sur ces outils pour filtrer les courriels et les mémos pertinents dans des bases de données dépassant souvent le téraoctet d'informations. L'Association du Barreau Américain note dans un rapport sur la technologie juridique que l'efficacité de ces tris automatisés influence désormais la stratégie des litiges complexes.
Une Domination Technologique Contestée par les Modèles de Langue
L'émergence des transformateurs et des modèles de langage de grande taille remet en question l'hégémonie de cette méthode de calcul. Des chercheurs de l'Institut national de recherche en informatique et en automatique (INRIA) soulignent que les approches purement statistiques ignorent le contexte sémantique et les synonymes. Selon une étude publiée sur le portail HAL Science, les représentations vectorielles modernes capturent mieux les nuances du langage humain que le simple comptage de mots.
Cette limite technique entraîne parfois des résultats imprécis lorsque deux mots différents désignent le même concept. Les systèmes basés uniquement sur la fréquence ne parviennent pas à établir de lien entre le terme voiture et le terme véhicule si l'un d'eux est absent du document source. Pour pallier cette faiblesse, les développeurs intègrent désormais des couches de réseaux de neurones qui travaillent conjointement avec les méthodes traditionnelles de pondération.
Les Défis de l'Évolutivité dans le Big Data
La gestion de volumes massifs de données impose des contraintes matérielles sévères aux infrastructures de calcul. L'hébergement de l'index inversé nécessaire au fonctionnement de ces algorithmes requiert des capacités de mémoire vive considérables. Les ingénieurs d'Amazon Web Services rapportent que la maintenance de ces structures de données représente un coût opérationnel significatif pour les fournisseurs de services en nuage.
La mise à jour en temps réel des statistiques globales d'une collection constitue un autre obstacle majeur. Chaque ajout de document modifie potentiellement le poids de chaque mot dans l'ensemble du système, ce qui exige des recalculs périodiques complexes. Les experts du cabinet Gartner indiquent que les entreprises privilégient souvent des approximations statistiques pour maintenir des performances acceptables lors de l'indexation de flux de données continus.
La Persistance dans les Logiciels de Détection de Plagiat
Les services académiques de vérification de l'originalité des travaux utilisent largement la méthode Term Frequency Inverse Document Frequency pour identifier les similarités suspectes. Ces programmes comparent la signature statistique d'un devoir d'étudiant avec une vaste base de données de publications universitaires. Le ministère de l'Enseignement supérieur français encourage l'usage de ces outils pour garantir l'intégrité des diplômes délivrés.
L'identification des signatures lexicales uniques permet de repérer des structures de phrases calquées sur des sources non citées. Les éditeurs de logiciels spécialisés affirment que leur taux de détection des emprunts non autorisés a progressé de 15 pour cent grâce au raffinement des algorithmes de pondération. Cette efficacité repose sur la capacité du système à isoler les termes techniques peu communs qui caractérisent un sujet d'étude spécifique.
Les Implications Éthiques de la Hiérarchisation Automatisée
La manière dont les informations sont classées soulève des préoccupations croissantes concernant la neutralité des algorithmes. La Commission européenne examine régulièrement l'impact des systèmes de recommandation sur l'accès des citoyens à une information diversifiée. Les rapports de l'Observatoire de l'intelligence artificielle suggèrent que les biais statistiques inhérents aux fréquences de mots peuvent favoriser certains discours au détriment d'autres.
Les critiques soulignent que les termes populaires dans les médias dominants finissent par écraser les terminologies alternatives ou minoritaires. Cette concentration lexicale peut créer des chambres d'écho où seuls les sujets les plus fréquemment discutés restent visibles pour l'utilisateur final. Des sociologues spécialisés dans le numérique alertent sur le risque de standardisation culturelle induit par une dépendance excessive à ces mesures de pertinence mathématique.
L'Adaptation aux Langues Non-Européennes
L'application de ces calculs rencontre des difficultés particulières avec les langues qui ne marquent pas les espaces entre les mots, comme le mandarin ou le japonais. Les processus de segmentation préalable deviennent alors obligatoires pour définir ce qui constitue une unité lexicale de base. Les travaux de l'Organisation internationale de la Francophonie montrent que la diversité linguistique nécessite des ajustements constants des outils de traitement automatique.
Pour les langues à morphologie complexe, comme l'arabe ou le finnois, une simple racine peut générer des dizaines de formes différentes. Les systèmes doivent alors pratiquer la lemmatisation pour regrouper ces variations sous une entrée unique dans l'index. Sans cette étape cruciale, la statistique de fréquence serait diluée entre de multiples occurrences, faussant ainsi le calcul de l'importance réelle du concept traité.
Évolution Vers des Systèmes Hybrides
L'avenir de la recherche documentaire semble s'orienter vers une fusion entre les statistiques classiques et l'apprentissage profond. Les laboratoires de recherche de Meta et de Microsoft publient régulièrement des articles décrivant des architectures hybrides capables de traiter simultanément la fréquence brute et l'intention de recherche. Ces nouveaux modèles conservent la rapidité des méthodes traditionnelles tout en ajoutant une compréhension fine des requêtes complexes.
L'intégration de la sémantique permet de répondre à des questions posées en langage naturel plutôt que de simplement faire correspondre des mots-clés. L'Agence nationale de la sécurité des systèmes d'information (ANSSI) surveille ces évolutions pour sécuriser les méthodes de recherche dans les bases de données sensibles. L'enjeu consiste à maintenir la transparence des résultats alors que les couches de décision deviennent de plus en plus opaques pour les auditeurs humains.
Les développeurs travaillent actuellement sur des techniques de compression de données pour réduire l'empreinte carbone des grands centres de serveurs. La consommation énergétique liée au traitement constant de gigantesques index statistiques est devenue une préoccupation centrale pour les autorités de régulation environnementale. Les prochaines générations de systèmes de tri devront prouver leur efficacité énergétique autant que leur précision sémantique pour rester viables dans le cadre des accords climatiques internationaux.
Le déploiement des protocoles de recherche dans les environnements de réalité augmentée représente le prochain défi majeur pour ces algorithmes de classification. Les systèmes devront indexer non seulement des textes, mais aussi des objets et des interactions spatiales traduits en jetons numériques. Les experts du secteur technologique prévoient que les fondements de la statistique documentaire devront être adaptés pour traiter des flux de données provenant de capteurs biométriques et environnementaux d'ici 2030.



