J'ai vu un chef de projet perdre trois semaines de travail et environ 15 000 euros de budget de conseil parce qu'il pensait qu'un simple coup d'œil sur le Tableau De La Loi Normale suffisait pour valider ses tests d'échantillonnage. Il avait une colonne de chiffres, une moyenne, un écart-type, et il a foncé tête baissée dans ses calculs de probabilités sans vérifier si ses données brutes avaient même la forme d'une cloche. Résultat : il a prédit un taux de défaut de 2 % pour une chaîne de production alors qu'en réalité, à cause d'une distribution asymétrique qu'il n'avait pas détectée, le taux réel frôlait les 8 %. Dans l'industrie, ce genre d'écart n'est pas une simple erreur d'arrondi, c'est une faute professionnelle qui ruine la rentabilité d'un trimestre entier. On ne manipule pas ces outils mathématiques comme on remplit un tableur Excel basique ; il y a des pièges structurels qui attendent les imprudents.
L'illusion de la symétrie parfaite et le piège du zéro central
La première erreur, celle que je vois commise par 90 % des débutants, c'est de croire que toutes les données se répartissent sagement de part et d'autre de la moyenne. C'est une vision théorique qui ne survit jamais au contact du terrain. Dans le monde réel, les files d'attente, les revenus ou les temps de panne ne sont presque jamais symétriques. Si vous appliquez aveuglément cette approche à des données "biaisées", vous allez obtenir des probabilités qui n'ont aucun sens physique.
L'erreur consiste à ne pas tester la normalité avant d'ouvrir la documentation. On se jette sur la valeur $Z$ alors qu'on devrait d'abord regarder un histogramme ou un diagramme quantile-quantile. Si votre distribution a une "queue" interminable vers la droite, votre calcul de probabilité sera faux. J'ai vu des analystes logistiques prévoir des stocks de sécurité insuffisants parce qu'ils utilisaient la règle des trois sigmas sur des temps de livraison qui, par nature, ne peuvent pas être inférieurs à zéro mais peuvent exploser en cas de grève.
La solution est brutale : si vos tests de Shapiro-Wilk ou de Kolmogorov-Smirnov échouent, rangez votre outil habituel. Vous devez soit transformer vos données, par exemple avec un logarithme, soit passer à des méthodes non paramétriques. N'essayez pas de forcer la réalité à entrer dans une cloche de Gauss si elle n'en a pas envie. Ça vous coûtera votre crédibilité et celle de votre service.
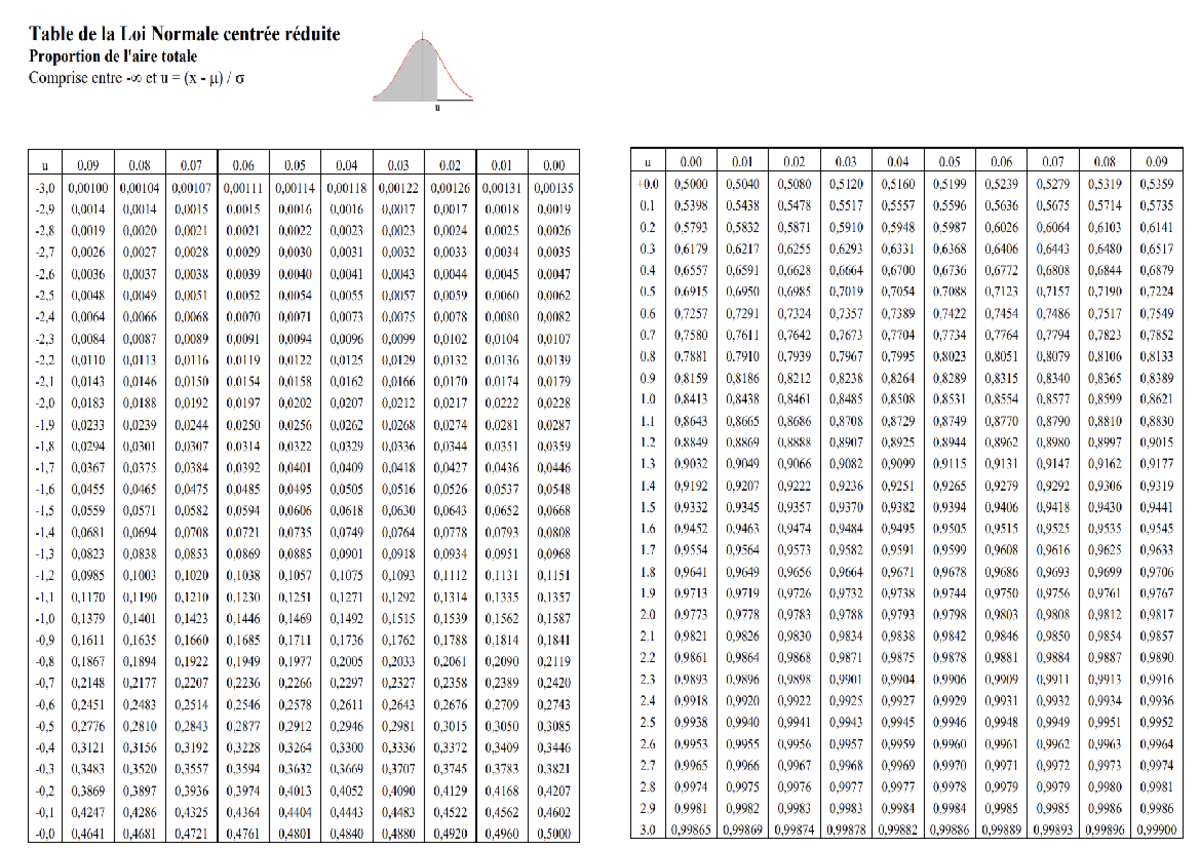
Pourquoi votre Tableau De La Loi Normale est probablement mal utilisé
On arrive au cœur du problème technique : la lecture même de l'outil. Il existe plusieurs versions de ce document de référence, et se tromper de version, c'est l'assurance d'un contresens total. Certaines listent les probabilités de $-\infty$ à $Z$, d'autres de $0$ à $Z$, et d'autres encore ne donnent que la queue de distribution. Si vous ne vérifiez pas le petit schéma en haut de la page, vous risquez de vous tromper d'un facteur 0,5 dans vos probabilités.
Imaginez la scène : vous présentez un rapport à votre direction sur les risques de dépassement de budget. Vous annoncez fièrement une probabilité de 15 %. En réalité, parce que vous avez lu la mauvaise colonne du Tableau De La Loi Normale, le risque est de 35 %. C'est la différence entre une gestion prudente et une catastrophe financière. J'ai vu des ingénieurs expérimentés se prendre les pieds dans le tapis simplement parce qu'ils utilisaient une version de la table apprise à l'université alors que leur logiciel d'entreprise utilisait une autre convention de calcul.
La confusion entre $P(X < x)$ et $P(X > x)$
C'est le classique du genre. On cherche la probabilité d'être "au-dessus" d'un seuil, mais on lit la valeur qui correspond à être "en-dessous". Dans une étude d'assurance, inverser ces deux concepts signifie soit surévaluer massivement vos primes et perdre tous vos clients, soit les sous-évaluer et risquer la faillite au premier sinistre majeur. Vous devez toujours dessiner votre courbe à la main, hachurer la zone qui vous intéresse, et vérifier visuellement si le chiffre que vous sortez de la table est cohérent avec votre dessin. Si votre zone hachurée représente moins de la moitié de la courbe et que votre table vous donne 0,84, c'est que vous faites une erreur de lecture.
Oublier que la loi normale n'est qu'une approximation
On nous répète que grâce au théorème central limite, tout finit par ressembler à une loi normale si l'échantillon est assez grand. C'est le plus grand mensonge enseigné en statistiques de base. "Assez grand", dans l'esprit de beaucoup, c'est $n = 30$. C'est faux. Si vos données de base sont chaotiques ou issues d'un processus multiplicatif, même avec 100 ou 200 points, la convergence peut être médiocre.
L'erreur ici est de croire que la taille de l'échantillon absout tous les péchés de la collecte de données. Dans le secteur bancaire, on a vu ce que donnait l'excès de confiance dans ces modèles lors de crises systémiques. Les événements extrêmes, ce qu'on appelle les "queues épaisses", se produisent bien plus souvent que ce que la théorie prévoit. En vous basant uniquement sur cette stratégie classique, vous ignorez volontairement les cygnes noirs.
La solution pratique est d'ajouter systématiquement des tests de robustesse. Ne vous contentez pas d'une seule méthode de calcul. Si vous travaillez sur des enjeux financiers lourds, utilisez des simulations de Monte Carlo en parallèle. Si les deux méthodes divergent de plus de 5 %, c'est que votre hypothèse de normalité est une béquille cassée. N'attendez pas que le système s'effondre pour réaliser que vos données n'étaient pas "normales".
Le désastre de l'arrondi prématuré
Voici comment on perd des milliers d'euros en trois étapes simples. On calcule la moyenne avec deux décimales. On calcule l'écart-type avec une seule. On calcule la valeur $Z$, on l'arrondit pour qu'elle "rentre" dans les lignes du Tableau De La Loi Normale, et on sort une probabilité. À chaque étape, vous avez injecté du bruit et de l'erreur dans votre système.
L'effet papillon des décimales
Dans un processus de contrôle qualité de haute précision, comme la fabrication de micro-processeurs ou de pièces aéronautiques, une erreur sur la troisième décimale de la valeur $Z$ peut se traduire par des milliers de pièces rejetées à tort (ou pire, acceptées alors qu'elles sont défectueuses). J'ai audité une usine où le logiciel interne arrondissait les calculs intermédiaires. En recalculant tout avec une précision flottante complète, on a découvert que leur taux de rebut "théorique" était sous-estimé de 12 %.
Comparez ces deux approches dans un contexte de gestion de stock.
- Avant : L'analyste prend une demande moyenne de 100 unités, un écart-type de 15. Il veut un niveau de service de 95 %. Il regarde sa table, prend la valeur $Z$ de 1,64. Il commande 124,6 unités, arrondi à 125. Il ne comprend pas pourquoi il tombe en rupture de stock un mois sur six.
- Après : L'analyste réalise que sa demande suit une loi de Poisson, pas une loi normale, car les volumes sont faibles et les commandes irrégulières. Il utilise un modèle adapté. Il découvre que pour garantir réellement 95 %, il doit stocker 132 unités. Ces 7 unités de différence semblent dérisoires, mais sur 500 références produits, c'est la différence entre une entreprise qui livre à temps et une entreprise qui perd ses contrats cadres.
La précision n'est pas une coquetterie d'universitaire, c'est une nécessité opérationnelle. Si vous devez utiliser une table papier ou un PDF, ne vous contentez pas de la valeur la plus proche. Faites une interpolation linéaire entre les deux valeurs les plus proches. C'est une manipulation de trente secondes qui vous évite des erreurs grossières.
Ne pas comprendre l'unité de mesure de l'écart-type
C'est sans doute l'erreur la plus "bête", mais je la vois passer dans des rapports de consultants payés à prix d'or. La valeur $Z$ que vous cherchez dans votre document de référence n'est pas un nombre brut, c'est un nombre d'écarts-types. Si vous mélangez les unités — par exemple en divisant des euros par des pourcentages ou des millimètres par des centimètres — tout votre processus s'écroule.
J'ai vu un cas où une équipe de maintenance préventive calculait l'usure de pneus de flottes de camions. Ils avaient la moyenne en kilomètres, mais l'écart-type leur avait été transmis en milles (miles). Personne n'a vérifié. Ils ont utilisé leurs chiffres directement dans leur processus de calcul. Ils ont fini par ordonner le remplacement de pneus qui étaient encore à 40 % de leur capacité de vie, jetant littéralement de l'argent par les fenêtres, tout ça parce que la valeur $Z$ obtenue n'avait aucun sens physique mais "semblait" correcte sur le papier.
Vérifiez toujours la cohérence dimensionnelle. Si votre moyenne est en $kg$, votre écart-type doit être en $kg$. La valeur $Z$ doit être adimensionnelle. C'est le b.a.-ba, mais sous la pression d'une échéance, c'est la première chose que les gens oublient de vérifier.
Le danger de l'extrapolation hors contexte
On utilise souvent cette méthode pour prédire le futur en se basant sur le passé. C'est là que le piège se referme. Les conditions qui ont rendu vos données "normales" l'année dernière ne sont peut-être plus réunies aujourd'hui. Une modification dans votre chaîne d'approvisionnement, un changement de réglementation européenne ou même une variation climatique peuvent briser la distribution de vos données.
J'ai travaillé avec une chaîne de distribution qui utilisait des modèles basés sur la loi normale pour prévoir la fréquentation de leurs magasins. Tout fonctionnait bien jusqu'à ce qu'un concurrent ouvre à deux kilomètres. La distribution de la fréquentation n'a pas juste "glissé", elle est devenue bimodale (deux pics). Continuer à utiliser une moyenne unique et un écart-type global revenait à piloter un avion avec un altimètre cassé. Ils prévoyaient pour un "client moyen" qui n'existait plus.
La solution est de ne jamais considérer vos paramètres comme acquis. Vous devez recalculer vos indicateurs de forme (skewness et kurtosis) tous les trimestres, ou dès qu'un changement majeur survient dans votre environnement business. Si ces indicateurs dérivent, votre modèle est mort.
La vérification de la réalité
Soyons honnêtes : personne n'aime passer des heures à vérifier des hypothèses statistiques alors que la direction veut des réponses hier. Mais voici la réalité du terrain : les outils comme le Tableau De La Loi Normale sont des simplifications extrêmes d'une réalité complexe. Ils ne sont utiles que si vous respectez scrupuleusement les conditions de leur application.
Réussir avec ce sujet demande trois choses que la plupart des gens n'ont pas envie de faire :
- Douter de ses données : Partez du principe qu'elles sont biaisées, incomplètes ou mal mesurées jusqu'à preuve du contraire.
- Maîtriser l'outil, pas juste la lecture : Comprenez comment la table est construite. Si vous ne savez pas recalculer une valeur $Z$ à la main ou via une fonction simple, vous ne devriez pas utiliser le résultat pour prendre des décisions financières.
- Accepter l'incertitude : Une probabilité de 95 % n'est pas une certitude. C'est un risque de 5 % de se tromper lourdement. Si ce risque de 5 % peut couler votre boîte, alors votre modèle n'est pas la solution, c'est une partie du problème.
Si vous cherchez un raccourci magique pour éviter ces étapes, vous ne le trouverez pas. La statistique est une discipline de rigueur, pas d'intuition. Soit vous faites le travail de vérification en amont, soit vous payez le prix du nettoyage des dégâts en aval. Le choix semble simple quand on regarde les chiffres, mais l'ego pousse souvent à choisir la facilité. Ne soyez pas cet analyste qui doit expliquer en réunion de crise pourquoi ses prévisions étaient à côté de la plaque parce qu'il a eu la flemme de vérifier une hypothèse de base.
- Vérifiez la normalité avec des tests formels.
- Validez la convention de votre table (0 à $Z$ ou $-\infty$ à $Z$).
- Maintenez une précision maximale dans vos calculs intermédiaires.
- Recalculez vos paramètres dès que le contexte change.
C'est ça, la réalité du métier. Le reste, c'est de la littérature pour les manuels scolaires.



