On vous a menti sur la nature même de l'erreur informatique. Dans les open spaces de la Silicon Sentier ou les bureaux feutrés des banques de La Défense, une légende urbaine persiste parmi les développeurs : celle de la gomme magique. On imagine que le Reverting A Commit In Git est l'équivalent numérique d'un voyage dans le temps, une manière propre d'effacer une bévue sans laisser de traces. C'est une illusion confortable. La réalité technique, celle que je documente depuis dix ans en observant les infrastructures s'effondrer sous le poids de mauvaises décisions, est bien plus brutale. Reverser n'efface rien. C'est un acte chirurgical qui ajoute de la complexité à la complexité, un pansement que l'on colle sur une plaie ouverte en espérant que le sang ne traversera pas la gaze. Si vous pensez que cette commande est votre filet de sécurité, vous faites fausse route. Elle est souvent le premier domino d'une catastrophe systémique.
L'anatomie d'une cicatrice permanente
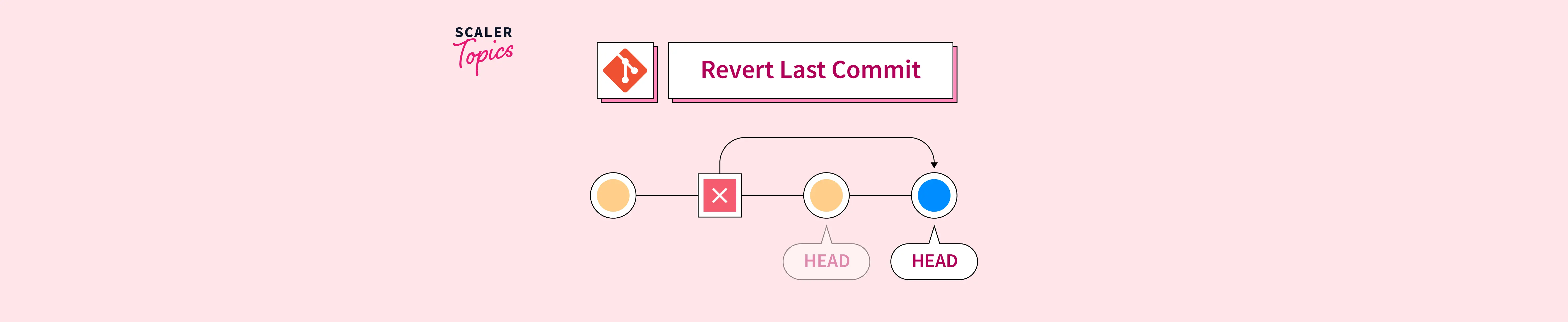
Le premier choc pour quiconque s'approche des entrailles de la gestion de version, c'est de comprendre que le système ne recule jamais. Contrairement à ce que suggère le langage courant, faire marche arrière dans l'historique d'un projet ne signifie pas supprimer le passé. En informatique, le passé est une sédimentation immuable. Quand vous déclenchez cette opération, vous ne demandez pas au logiciel de redevenir ce qu'il était. Vous créez un nouvel événement, une nouvelle entité qui porte en elle la négation de l'entité précédente. C'est un paradoxe ontologique qui s'installe au cœur de votre code source. Vous avez maintenant deux erreurs au lieu d'une : l'erreur originale, qui reste gravée dans le marbre de l'historique, et la correction qui tente de l'annuler, ajoutant encore du bruit à la communication de votre équipe.
Cette distinction n'est pas qu'une querelle de sémantique pour puristes. Elle a des conséquences directes sur la stabilité de vos déploiements. J'ai vu des entreprises entières paralyser leur production parce qu'elles croyaient que cette manipulation était anodine. En réalité, chaque fois que vous injectez une inversion, vous créez un risque de conflit futur lors de la fusion des branches. C'est une dette technique invisible qui s'accumule. Le système devient une forêt de miroirs où il devient impossible de distinguer le code légitime de la correction de la correction. On ne répare pas un vase brisé en recollant les morceaux un par un ; on finit avec un objet fragile, plein de cicatrices, dont la structure interne est compromise.
Le Reverting A Commit In Git Face Au Chaos Des Dépendances
Le danger se multiplie dès que l'on sort de l'isolement d'un petit projet personnel. Dans une architecture moderne, où chaque micro-service dépend de dix autres, l'idée de neutraliser un changement spécifique est un pari risqué. Le système de gestion de version ne voit que le texte, pas la logique métier. Il ne sait pas que votre modification a déclenché une mise à jour de schéma dans une base de données distante ou qu'elle a invalidé un cache sur un serveur à l'autre bout de l'Europe. En exécutant le Reverting A Commit In Git, vous déconnectez la réalité du code de la réalité de l'infrastructure. Vous vous retrouvez dans un état hybride, un purgatoire technique où le logiciel pense être revenu en arrière alors que ses effets de bord continuent de hanter le réseau.
Le sceptique vous dira sans doute que c'est toujours mieux que de laisser un bug en production. C'est l'argument de la moindre douleur. On me rétorque souvent qu'il vaut mieux une trace sale dans l'historique qu'un service indisponible. C'est une fausse dichotomie. Ce raisonnement ignore l'existence de stratégies bien plus saines comme le déploiement de correctifs explicites ou l'utilisation de verrous de fonctionnalités. Préférer l'inversion automatique, c'est choisir la paresse intellectuelle plutôt que la rigueur de l'analyse. C'est traiter le symptôme sans comprendre la maladie. Lorsque vous inversez, vous perdez souvent le contexte de pourquoi la modification initiale a été faite, ce qui garantit presque à coup sûr que quelqu'un d'autre commettra la même erreur trois mois plus tard.
L'illusion de la propreté et le poids du passé
La culture de l'immédiateté nous a rendus allergiques à la persistance de l'erreur. On veut que nos outils de travail soient aussi éphémères que des messages qui s'autodétruisent. Pourtant, le génie logiciel repose sur la traçabilité. Les ingénieurs qui réussissent ne sont pas ceux qui cachent leurs fautes sous des couches d'inversions automatisées, mais ceux qui assument la linéarité du temps. Quand on regarde les grands projets open source, ceux qui durent depuis des décennies, on remarque une méfiance instinctive envers les solutions de facilité qui polluent la chronologie des changements. Chaque modification doit être un pas en avant, même si ce pas sert à corriger une direction erronée.
On ne peut pas simplement ignorer le coût cognitif pour les nouveaux arrivants dans un projet. Imaginez un développeur qui rejoint votre équipe demain. Il parcourt l'historique et voit une suite de mouvements contradictoires, des allers-retours incessants qui ne racontent aucune histoire cohérente. Il perd un temps précieux à essayer de comprendre si une fonctionnalité a été retirée intentionnellement ou par accident. La clarté est la politesse du codeur. En abusant de ces mécanismes de retour en arrière, vous transformez votre journal de bord en un rébus illisible. Vous détruisez la confiance que vos pairs peuvent avoir dans la stabilité de la base de code, car rien n'y semble définitif.
Une question de culture plutôt que de commande
Au fond, le problème ne vient pas de l'outil, mais de la mentalité qui l'accompagne. On utilise ces fonctions comme une issue de secours parce qu'on a peur du jugement de l'historique. C'est une forme de vanité technique. Nous voulons paraître infaillibles, alors nous essayons de masquer nos tâtonnements. Mais un historique de code n'est pas un portfolio de design ; c'est un document légal et technique qui doit refléter la vérité de ce qui a été construit. La vérité est parfois désordonnée. Elle comporte des fausses routes et des impasses. Vouloir les gommer artificiellement, c'est s'interdire d'apprendre de ses propres échecs.
Je me souviens d'un incident majeur chez un hébergeur européen où une série d'inversions en cascade avait fini par rendre le système totalement instable. Les ingénieurs, paniqués, ne savaient plus quelle était la version de référence. Ils avaient tellement joué avec la chronologie qu'ils avaient créé des boucles logiques insolubles. La solution n'est pas venue d'une commande de plus, mais d'un arrêt total, d'une remise à plat et d'une acceptation du fait que la seule issue était de reconstruire vers l'avant. On ne répare pas le futur en triturant le passé. On le répare en prenant des décisions claires dans le présent, sans chercher de raccourci technique qui masquerait notre responsabilité individuelle.
L'expertise ne consiste pas à savoir comment effacer ses traces avec élégance, mais à posséder la discipline nécessaire pour ne jamais avoir besoin de prétendre que l'erreur n'a pas eu lieu. Un développeur qui assume son commit défectueux et publie un correctif explicite montre une compréhension bien plus profonde des systèmes complexes que celui qui se cache derrière une automatisation de retour arrière. C'est une leçon d'humilité face à la machine. Chaque ligne de code que nous écrivons est un engagement, et aucun artifice technique ne devrait nous permettre de nous soustraire aux conséquences de cet engagement.
La gestion de version est une science de la mémoire, pas un outil d'amnésie collective. Plus vite on accepte que chaque action est une cicatrice indélébile sur le corps du logiciel, plus vite on commence à coder avec la prudence et la précision que le métier exige. Le confort du retour en arrière facile est le berceau de la négligence technique. On se permet de tester en production, on se permet de ne pas vérifier ses tests unitaires, on se permet l'approximation, parce qu'on se dit que l'on pourra toujours annuler d'un clic. C'est cette mentalité qui fragilise le web et nos infrastructures critiques au quotidien.
Le code n'est pas une ardoise magique que l'on secoue pour tout effacer, c'est un testament de notre pensée logique dont chaque rature fait partie intégrante du récit.



