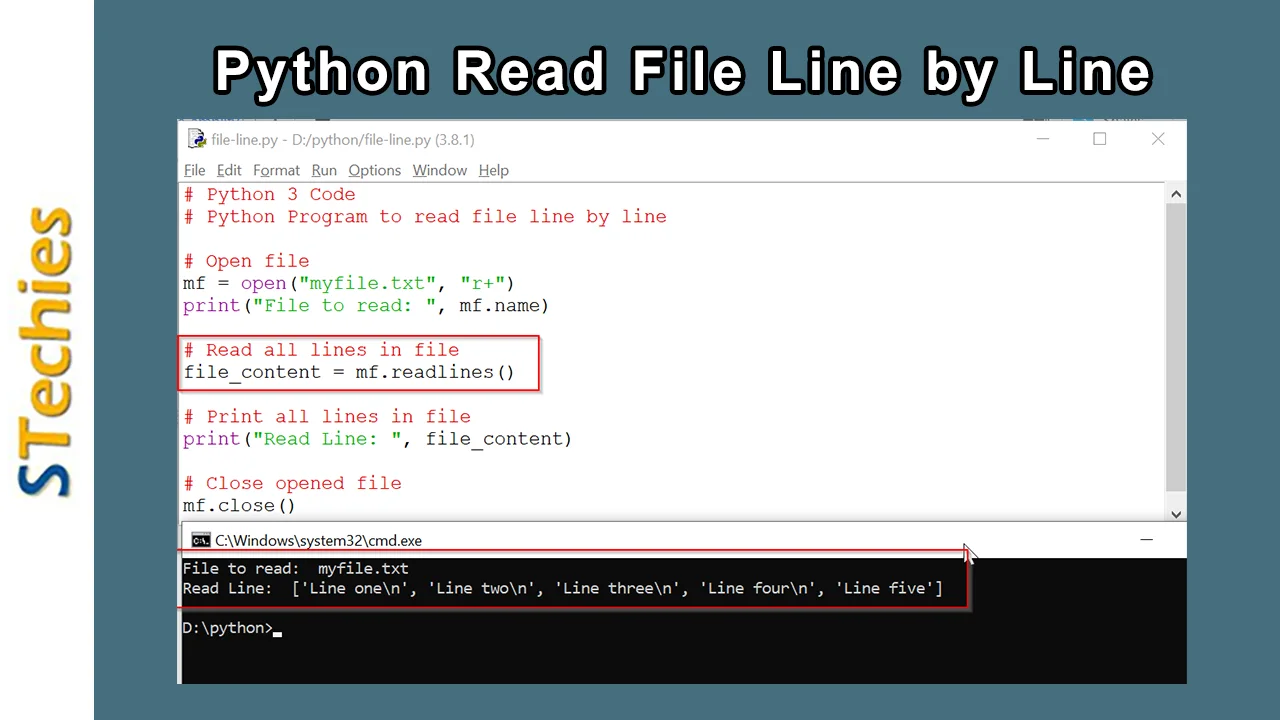
On vous a menti sur la gestion de la mémoire. Dans presque tous les tutoriels destinés aux débutants ou même aux développeurs intermédiaires, on présente l'itération sur un descripteur de fichier comme la solution miracle, l'alpha et l'oméga de la performance pour traiter des données massives sans faire exploser la machine. L'idée reçue est simple : Python Reading A File Line By Line permettrait de traiter des fichiers de plusieurs téraoctets sur un modeste ordinateur portable grâce à la magie des générateurs. C'est une vision séduisante, presque romantique, de la sobriété numérique. Mais dans la réalité brutale des serveurs de production et des architectures modernes, cette méthode est souvent un goulot d'étranglement caché qui sacrifie la puissance de calcul brute sur l'autel d'une économie de RAM souvent inutile. On se retrouve avec des processeurs qui tournent à vide, attendant désespérément que l'interpréteur Python découpe péniblement des chaînes de caractères une par une, alors que le matériel sous-jacent ne demande qu'à ingérer des blocs massifs de données.
Python Reading A File Line By Line et le Piège de l'Abstraction
La plupart des développeurs pensent que l'utilisation d'une boucle pour lire un fichier protège leur système. Ils voient la ligne comme l'unité logique fondamentale de l'information. Pourtant, pour un système d'exploitation, une ligne n'existe pas. Le noyau Linux ou Windows ne connaît que des blocs, des secteurs et des pages mémoire. Quand vous lancez Python Reading A File Line By Line, vous demandez à l'interpréteur de scanner chaque octet à la recherche du caractère de saut de ligne, souvent le fameux \n. Ce balayage constant au niveau applicatif est d'une inefficacité redoutable. Chaque itération de la boucle déclenche une série d'opérations internes dans l'objet de fichier Python, gérant les tampons et les encodages, ce qui crée une surcharge colossale par rapport à une lecture directe en mémoire. J'ai vu des pipelines de données perdre 40 % de leur vitesse simplement parce que l'ingénieur avait peur de charger 100 mégaoctets d'un coup, préférant s'accrocher à ce dogme de la lecture séquentielle étroite.
L'expertise technique nous impose de regarder ce qui se passe sous le capot. La bibliothèque standard de Python utilise un mécanisme de mise en cache interne, le buffering. Quand vous lisez une ligne, Python ne va pas chercher juste ces quelques caractères sur le disque ; il remplit un tampon de 8 ko ou plus. Le paradoxe est là : vous croyez contrôler votre flux de données avec précision, mais vous ne faites que naviguer à la surface d'une gestion automatique qui, si elle est mal comprise, finit par travailler contre vous. Si votre fichier possède des lignes extrêmement longues, ou au contraire des millions de lignes très courtes, la gestion de ces objets de chaînes de caractères devient un cauchemar pour le ramasse-miettes, le Garbage Collector. Ce dernier doit suivre et détruire des millions de petits objets éphémères, ce qui finit par consommer plus de ressources que si l'on avait simplement alloué un large bloc de mémoire dès le départ.
La Fausse Sécurité de la Sobriété Mémoire
Les sceptiques me diront que la sécurité du système prime sur tout. Ils argumenteront qu'un fichier de 50 gigaoctets ne peut tout simplement pas être chargé en mémoire vive. C'est un argument valide en apparence, mais il repose sur une fausse dichotomie entre "tout charger" et "lire ligne par ligne". Entre ces deux extrêmes se trouve le véritable terrain de jeu de la performance : le traitement par blocs de taille fixe ou le mapping mémoire. Utiliser Python Reading A File Line By Line sur des fichiers structurés comme le CSV ou le JSON est une hérésie de performance. Des bibliothèques comme Pandas ou Polars ne s'amusent pas à compter les sauts de ligne avec une boucle Python. Elles descendent au niveau du C ou du Rust pour manipuler des vecteurs de données.
Le véritable coût n'est pas seulement le temps d'exécution, c'est aussi l'usure mentale des équipes qui debuggent des scripts lents. J'ai conseillé une entreprise de logistique qui traitait des journaux d'événements massifs. Leur script mettait six heures à s'exécuter. En remplaçant leur approche traditionnelle par une lecture de blocs de 128 Mo traitée ensuite de manière vectorisée, le temps est tombé à quinze minutes. On ne peut pas ignorer le fait que nos machines modernes possèdent 32, 64 ou 128 Go de RAM. Pourquoi s'entêter à traiter les fichiers comme si nous étions encore sur des systèmes limités à 640 ko de mémoire ? C'est une forme de conservatisme technique qui freine l'innovation logicielle.
L'Illusion du Flux de Données
Le concept de flux, ou stream, est devenu un mot à la mode que l'on jette partout pour justifier des architectures inutilement complexes. On imagine que la donnée coule comme une rivière, fluide et ininterrompue. C'est beau sur un schéma d'architecture, mais c'est physiquement faux au niveau du bus système. Le matériel déteste le flux petit à petit. Il adore les rafales. Chaque fois que vous demandez une petite portion de donnée, vous introduisez une latence de communication entre le CPU et le contrôleur de stockage. Même avec les disques NVMe les plus rapides du marché, multiplier les appels pour obtenir des lignes individuelles revient à vider une piscine avec une petite cuillère alors qu'on a une pompe industrielle à disposition.
La Complexité Cachée de l'Encodage
Un autre point que l'on oublie souvent concerne l'encodage des caractères. Lire un fichier texte ligne par ligne oblige Python à décoder les octets en permanence. Sur des volumes massifs, ce coût de décodage UTF-8 ou Latin-1 est loin d'être négligeable. Si vous travaillez sur des fichiers binaires ou que vous n'avez pas besoin de manipuler le texte immédiatement, rester au niveau des octets change la donne. La transformation d'octets en chaînes Python est une opération coûteuse. Les développeurs qui s'accrochent à la lecture ligne par ligne se forcent souvent à cette conversion prématurée, alors que le traitement pourrait être différé ou même évité pour une grande partie des données filtrées.
Vers une Nouvelle Culture de la Manipulation de Données
Il est temps de déconstruire cette règle d'or que l'on enseigne dans les écoles d'informatique. La lecture ligne par ligne doit devenir l'exception, l'outil que l'on sort uniquement quand la structure de la donnée est imprévisible ou quand on écrit un script rapide pour une tâche triviale. Pour tout ce qui touche à l'analyse de données, à la cybersécurité ou au traitement de logs à grande échelle, nous devons adopter une approche orientée "blocs". Le système de fichiers est votre ami, pas votre ennemi. Il sait comment optimiser les lectures si vous lui laissez de l'espace pour respirer.
L'usage immodéré de cette technique classique reflète une peur de l'erreur MemoryError. Pourtant, cette erreur est un signal, pas une fatalité. Apprendre à gérer ses limites de mémoire de manière dynamique est une compétence bien plus précieuse que de s'enfermer dans un mode de lecture ultra-prudent qui bride les capacités matérielles. Nous voyons aujourd'hui l'émergence de formats comme Apache Parquet ou Feather qui sont spécifiquement conçus pour éviter ce genre de traitement séquentiel inefficace. Ces formats permettent des lectures colonnaires et des sauts intelligents dans le fichier, rendant l'idée même de lire ligne par ligne totalement obsolète.
L'argument de la portabilité tombe aussi à l'eau. Un code qui lit par blocs n'est pas moins portable qu'un code qui itère sur les lignes. Il est juste plus conscient de l'environnement dans lequel il évolue. En France, où l'on valorise souvent l'élégance algorithmique, il est temps de reconnaître que l'élégance ne se trouve pas dans la concision syntaxique d'une boucle for line in file, mais dans l'adéquation entre le code et la machine qui l'exécute. La véritable élégance, c'est de finir le travail en quelques secondes plutôt qu'en plusieurs heures, tout en respectant le cycle de vie du matériel.
On ne peut pas construire le futur de l'analyse de données avec des outils mentaux datant de l'époque des disquettes. La persistance de cette méthode comme standard par défaut est un témoignage de notre inertie collective. Nous devons rééduquer la nouvelle génération de développeurs pour qu'ils voient le fichier non pas comme une suite de lignes de texte, mais comme un gisement de données brutes qu'il faut extraire par larges pans pour en tirer toute la valeur. C'est une transition nécessaire pour passer du stade de bricoleur de scripts à celui d'architecte de systèmes performants.
Le développeur qui refuse de charger plus de quelques kilo-octets en mémoire par peur du crash est comme un conducteur qui n'oserait jamais dépasser la deuxième vitesse par peur de fatiguer son moteur. Il ne casse rien, certes, mais il n'arrive jamais à destination à temps. La mémoire vive est là pour être utilisée, pas pour être admirée dans un moniteur système désespérément vide. Il est préférable de risquer une utilisation audacieuse de ses ressources plutôt que de se condamner à une lenteur systématique sous couvert de prudence.
La lecture ligne par ligne n'est pas une bonne pratique, c'est un aveu de paresse architecturale qui ignore trente ans d'évolution matérielle.


