Arrêtez de deviner le résultat de vos requêtes SQL. C'est l'erreur la plus fréquente que je vois chez les développeurs juniors et même certains analystes chevronnés qui pensent maîtriser les jointures alors qu'ils naviguent à vue. On se retrouve souvent face à ce dilemme technique : faut-il utiliser Left Inner Join vs Inner Join pour extraire des données cohérentes ? Si vous cherchez une réponse immédiate, sachez que l'un de ces termes est un abus de langage, tandis que l'autre est le pilier fondamental du langage SQL. Cette confusion coûte cher en performance et en intégrité des données, surtout quand on manipule des bases complexes sous PostgreSQL ou MySQL.
La réalité technique derrière le débat Left Inner Join vs Inner Join
Le premier secret à intégrer est simple. Le terme "Left Inner Join" n'existe pas de manière officielle dans la syntaxe standard SQL. C'est une erreur de syntaxe ou une confusion mentale entre deux concepts opposés : la jointure interne et la jointure externe gauche. En SQL, on choisit soit l'inclusion stricte, soit l'extension d'un côté.
Pourquoi cette confusion persiste dans les forums
Beaucoup de débutants mélangent les pinceaux car ils visualisent mal la théorie des ensembles. Ils veulent les données communes (le propre de l'interne) mais ont peur de perdre des lignes de la table principale. Ils inventent alors ce concept hybride dans leur esprit. Si vous tapez cela dans un éditeur comme DBeaver, vous recevrez une erreur de syntaxe immédiate. On utilise soit INNER JOIN, soit LEFT JOIN. L'idée de vouloir fusionner les deux est une quête impossible.
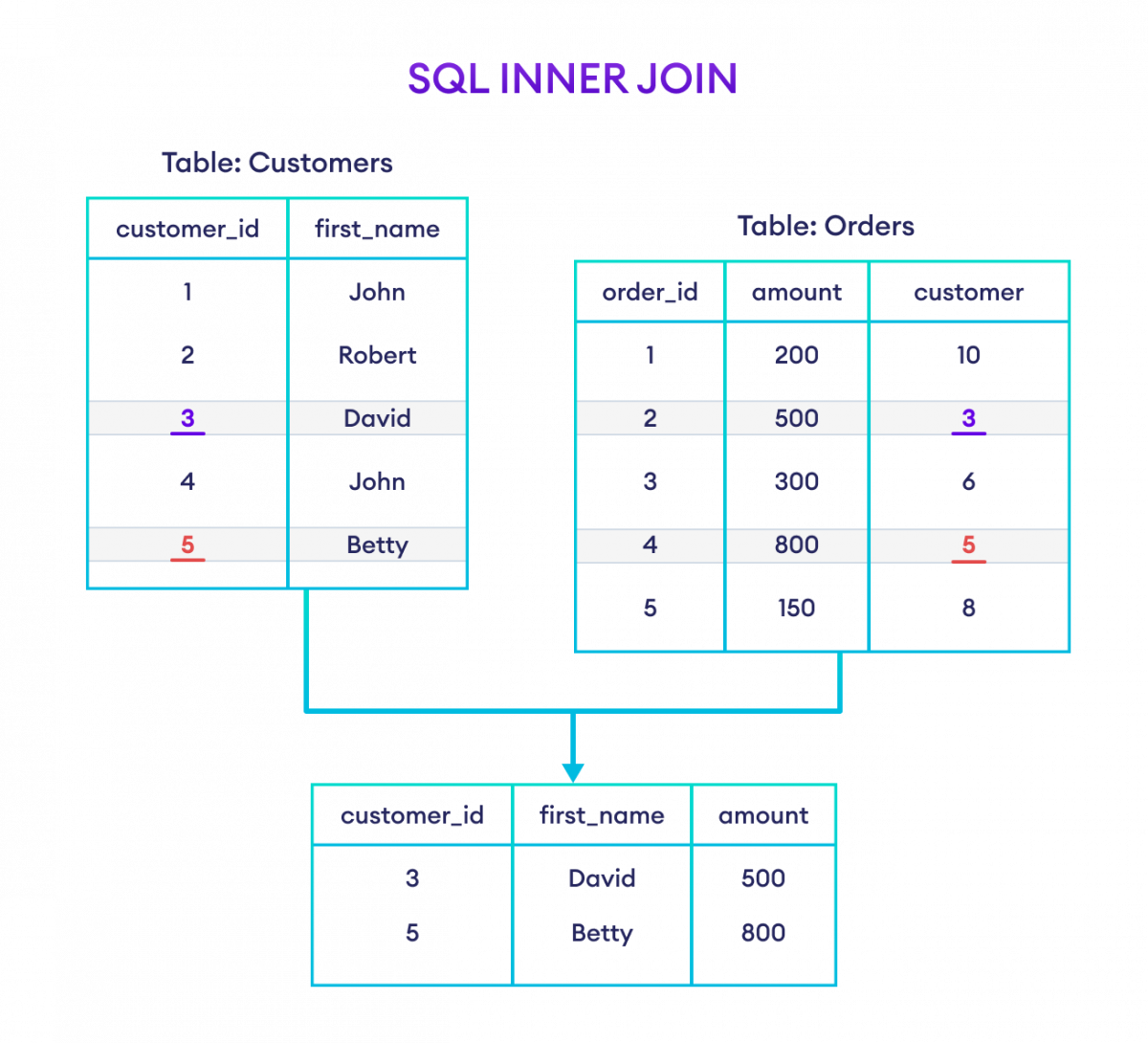
L'anatomie d'une jointure interne efficace
La jointure interne est l'outil de précision par excellence. Elle ne garde que ce qui correspond parfaitement des deux côtés. Imaginez une table "Commandes" et une table "Clients". Si vous faites une jointure interne, vous n'obtiendrez que les commandes passées par des clients répertoriés. Les clients sans commande disparaissent. Les commandes orphelines aussi. C'est propre. C'est net. On utilise cela quand la relation est obligatoire pour la logique métier.
Comprendre la mécanique de l'exclusion et de l'inclusion
Le choix impacte directement le volume de votre jeu de données final. C'est mathématique. Une jointure interne réduit presque toujours le nombre de lignes. Une jointure gauche, elle, préserve l'intégralité de votre point de départ.
Le comportement du Left Join face au vide
Quand on parle de jointure gauche, on accepte le vide. On dit à la base de données : "Donne-moi tout ce qu'il y a à gauche, et si tu trouves un correspondant à droite, affiche-le. Sinon, mets du NULL". C'est indispensable pour des rapports de performance. Par exemple, si vous voulez lister tous les produits de votre catalogue, même ceux qui n'ont jamais été vendus, c'est l'outil qu'il vous faut. La jointure interne, elle, supprimerait purement et simplement vos produits invendus de la liste.
La performance au scalpel
Sur des tables de plusieurs millions de lignes, la différence devient flagrante. Une jointure interne permet parfois à l'optimiseur de requêtes de filtrer les données plus tôt dans le processus d'exécution. Les index travaillent mieux. Le moteur de base de données comme MariaDB peut réduire l'espace de recherche de manière drastique. À l'inverse, une jointure gauche oblige le moteur à scanner la table de gauche entièrement, ce qui peut ralentir le traitement si vous n'avez pas de clauses WHERE restrictives.
Scénarios réels de production et erreurs fatales
J'ai vu des rapports financiers totalement faussés à cause d'une mauvaise utilisation de ces opérateurs. Une erreur classique consiste à utiliser une jointure interne alors qu'on veut calculer un taux de pénétration. Si vous filtrez les utilisateurs qui n'ont pas fait d'action, votre dénominateur est faux d'avance. Votre calcul est biaisé.
L'erreur du filtre après la jointure
C'est le piège numéro un. Vous faites un LEFT JOIN pour garder toutes vos lignes, mais vous ajoutez une condition dans le WHERE qui porte sur la table de droite. Résultat ? Votre jointure se transforme magiquement en jointure interne sans que vous le sachiez. Pourquoi ? Parce que le filtre WHERE élimine les valeurs NULL produites par la jointure gauche. Si vous voulez filtrer la table de droite tout en gardant toutes les lignes de gauche, la condition doit impérativement se trouver dans la clause ON. C'est une nuance que peu de gens saisissent avant de se brûler les ailes sur un projet critique.
Gérer les relations plusieurs-à-plusieurs
Dans les systèmes ERP complexes, les relations ne sont jamais simples. On se retrouve avec des tables de jointure intermédiaires. Utiliser des jointures internes en cascade peut faire fondre votre résultat comme neige au soleil. Parfois, on commence avec 10 000 lignes et on finit avec 3 lignes après quatre jointures internes successives. C'est souvent le signe d'une mauvaise compréhension du schéma de données ou d'une attente irréaliste sur la qualité des données saisies par les utilisateurs.
Optimisation et bonnes pratiques SQL en 2026
Aujourd'hui, les moteurs SQL sont intelligents, mais ils ne sont pas devins. Ils ne savent pas ce que vous avez derrière la tête. Le débat Left Inner Join vs Inner Join montre bien que la clarté de l'intention prime sur tout le reste.
L'importance des index sur les clés étrangères
Peu importe votre choix, sans index, votre base va ramer. C'est une certitude. Chaque colonne utilisée dans une clause ON devrait idéalement être indexée. Cela permet au moteur de faire des "Nested Loop Joins" ou des "Hash Joins" beaucoup plus rapidement. J'ai déjà vu des temps de réponse passer de 30 secondes à 10 millisecondes juste en ajoutant un index B-tree sur une colonne d'identifiant client. Ne négligez jamais l'analyse de votre plan d'exécution avec la commande EXPLAIN.
La lisibilité du code pour vos collègues
Le SQL est un langage de communication. Écrire INNER JOIN au lieu de simplement JOIN (qui est l'équivalent par défaut) montre que vous êtes explicite. C'est une politesse envers celui qui relira votre code dans six mois. Évitez les abréviations cryptiques. Nommez vos alias de table de façon claire. c pour clients, o pour orders. C'est basique, mais ça sauve des vies lors des sessions de débogage nocturnes.
Étapes concrètes pour choisir la bonne jointure
Pour ne plus jamais hésiter, suivez cette méthode simple lors de la rédaction de vos requêtes.
- Définissez votre table pivot. C'est la table qui contient l'entité principale que vous voulez compter ou lister. Si c'est une liste de clients, la table clients est votre base.
- Analysez la criticité de la relation. Est-ce qu'une ligne de la table A a un sens sans sa correspondance dans la table B ? Si la réponse est non, optez pour l'interne. Si la réponse est oui, passez sur une jointure gauche.
- Vérifiez la présence de NULL. Si vous utilisez une jointure gauche, préparez votre code applicatif ou votre outil de BI à gérer les valeurs manquantes. Utilisez des fonctions comme
COALESCEpour remplacer les NULL par des zéros ou des textes par défaut. - Testez avec des volumes représentatifs. Une requête qui fonctionne sur 100 lignes peut s'effondrer sur 1 000 000. Utilisez toujours un jeu de données de test qui ressemble à votre production.
- Inspectez le plan d'exécution. Tapez
EXPLAIN ANALYZEavant votre requête. Regardez les coûts. Si vous voyez un "Sequential Scan" sur une table énorme, c'est qu'il manque un index ou que votre jointure est mal pensée.
La maîtrise des jointures n'est pas une option pour quiconque travaille avec de la donnée. C'est la différence entre un bricoleur et un artisan. En comprenant que le concept hybride est une illusion et en choisissant délibérément entre l'inclusion totale et l'intersection, vous reprenez le contrôle sur vos bases de données. C'est ainsi qu'on construit des systèmes performants et des analyses auxquelles on peut enfin faire confiance. Les données ne mentent jamais, mais la façon dont on les lie peut raconter n'importe quoi si on n'y prend pas garde. Soyez rigoureux. Testez sans relâche. Le reste suivra.



