Votre serveur sature. Les alertes de monitoring s'affolent. Vous savez que quelque chose dévore vos gigaoctets, mais impossible de mettre la main sur le coupable entre les logs qui gonflent et les caches oubliés. Apprendre à Find Large Files On Linux n'est pas juste une compétence technique de plus, c'est l'outil de survie indispensable pour tout administrateur système ou utilisateur passionné qui refuse de voir sa machine ramer. On va voir ensemble comment débusquer ces fichiers massifs qui se cachent dans les recoins de votre arborescence, en utilisant des outils natifs et des astuces de vieux routiers du terminal.
Pourquoi votre disque dur est toujours plein
Le stockage est devenu bon marché, pourtant on manque toujours de place. C'est le paradoxe moderne. Sur un système Linux, les causes sont souvent les mêmes. Les fichiers de logs, par exemple. Un service mal configuré peut générer des gigaoctets de texte en quelques heures. On oublie aussi les paquets téléchargés. Quand on installe des logiciels, les gestionnaires comme APT ou DNF gardent parfois des copies locales des archives. C'est du gâchis.
Le piège des fichiers temporaires
Le répertoire /tmp est censé se vider tout seul. Parfois, ça rate. Un processus plante, laisse un fichier de 10 Go derrière lui, et votre système de fichiers commence à suffoquer. C'est frustrant. Vous devez vérifier régulièrement ces zones. Une autre source de frustration : les sauvegardes automatiques locales. On pense être en sécurité, mais on finit par saturer la partition racine avec des backups de backups.
La gestion des conteneurs et Docker
Si vous utilisez Docker, vous connaissez le problème. Les volumes inutilisés et les images orphelines s'accumulent. C'est silencieux. On ne s'en rend compte que quand le "No space left on device" apparaît. Nettoyer ces éléments est une priorité absolue.
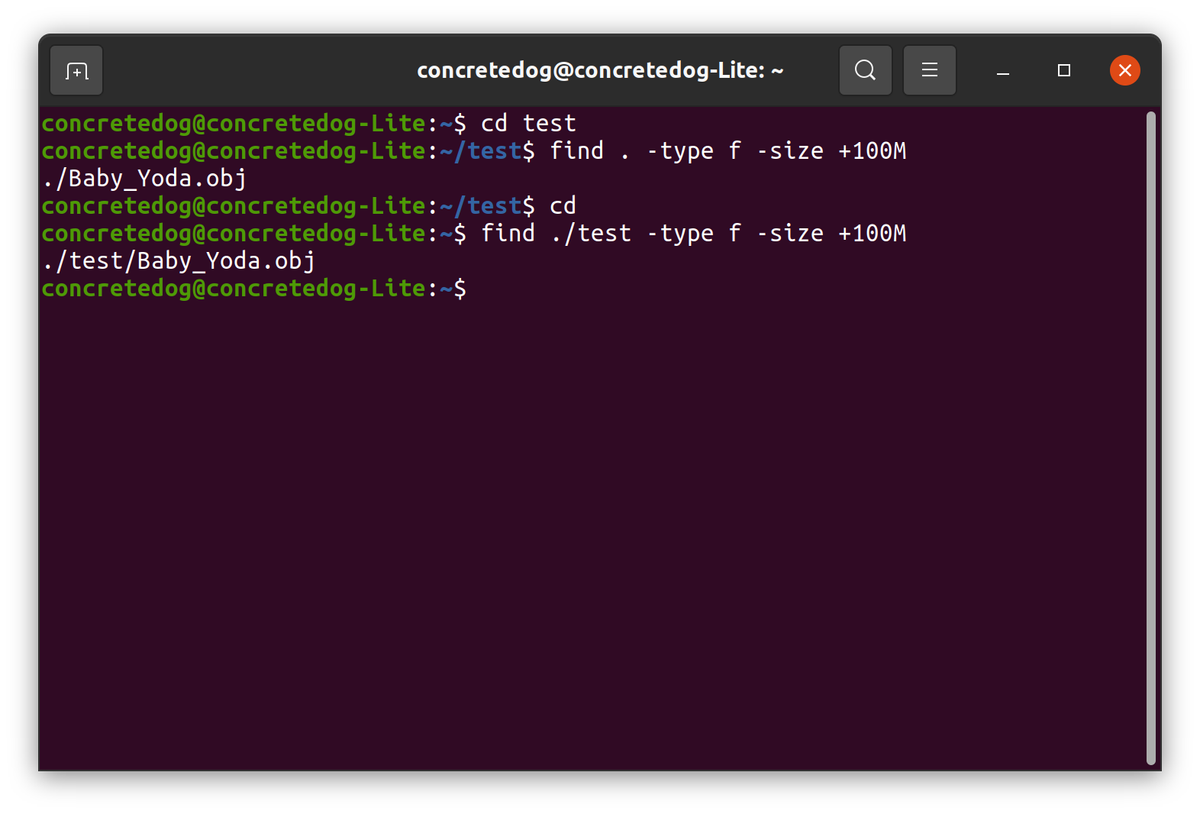
Les commandes natives pour Find Large Files On Linux
La commande find est votre meilleure amie. Elle est installée partout. Pas besoin de télécharger quoi que ce soit. Elle permet de filtrer par taille avec une précision chirurgicale. Si vous voulez chercher tout ce qui dépasse 500 Mo dans votre répertoire personnel, la syntaxe est simple. On utilise l'option -size. C'est rapide. C'est efficace.
Utiliser du pour une vision globale
La commande du (Disk Usage) offre une perspective différente. Elle ne cherche pas un fichier spécifique, elle analyse les dossiers. Je l'utilise souvent avec les options -ah. Le -a liste tout, le -h rend les chiffres lisibles pour un humain. C'est plus sympa de voir "2G" que des suites de chiffres interminables. Coupler du avec sort permet de classer les résultats instantanément. C'est l'approche que je privilégie quand je ne sais pas du tout où regarder.
L'astuce du tri par taille
Voici un exemple concret que j'utilise tout le temps : du -ah /var | sort -rh | head -n 20. Cette ligne de commande liste les 20 plus gros fichiers ou dossiers dans /var, classés par taille décroissante. Pourquoi /var ? Parce que c'est là que vivent les logs et les bases de données. C'est le point chaud habituel des serveurs Debian ou Ubuntu.
Des outils plus visuels pour gagner du temps
Le terminal c'est bien, mais parfois on veut voir la structure. L'outil Ncdu est une merveille. C'est une version améliorée de du avec une interface en mode texte. On navigue avec les flèches du clavier. On voit tout de suite quel dossier pèse lourd grâce à une barre de progression visuelle. Si vous avez accès à une interface graphique, des logiciels comme Baobab (Analyseur d'utilisation des disques) font un travail remarquable. Ils créent des cartes radiales. C'est très intuitif. On clique, on descend dans l'arborescence, on supprime. Simple.
Ncdu le sauveur de serveurs
Ncdu est léger. Il s'installe en deux secondes sur n'importe quelle distribution. Sa force réside dans sa capacité à scanner des systèmes de fichiers distants via SSH. C'est un gain de temps énorme. On évite de lancer dix commandes différentes pour comprendre l'organisation des données.
Le cas spécifique des systèmes de fichiers Btrfs ou ZFS
Ces systèmes gèrent l'espace différemment. Les snapshots peuvent consommer énormément de place sans que les commandes classiques ne le montrent clairement. Si vous utilisez OpenSUSE ou Fedora, faites attention à vos points de restauration. Un instantané système peut bloquer plusieurs gigaoctets de données supprimées, les empêchant d'être réellement libérées sur le disque.
Stratégies avancées pour Find Large Files On Linux
On peut aller plus loin en combinant les critères. Chercher les fichiers de plus de 1 Go modifiés il y a moins de deux jours ? C'est possible. On utilise -mtime. C'est l'approche idéale pour identifier une fuite de logs récente. Vous ciblez uniquement ce qui vient de changer.
Automatiser la surveillance
Pourquoi attendre que le disque soit plein ? Un petit script Cron peut faire le travail pour vous. Il scanne le disque une fois par semaine et vous envoie un mail si un fichier dépasse une certaine limite. C'est de la maintenance préventive. Ça évite les crises en plein milieu de la nuit parce qu'une base de données ne peut plus écrire ses transactions.
Gérer les fichiers cachés
On les oublie souvent. Les dossiers commençant par un point dans votre répertoire personnel. Les caches des navigateurs web ou des environnements de développement comme VS Code peuvent devenir monstrueux. Un ls -la ne suffit pas pour estimer leur poids. Utilisez systématiquement du -sch .[!.]* * pour inclure ces éléments cachés dans votre calcul total.
Erreurs classiques et comment les éviter
Supprimer un fichier avec rm ne libère pas toujours l'espace. C'est le piège classique. Si un processus tient encore le fichier ouvert, l'espace reste réservé. Le fichier est "supprimé" du point de vue de l'utilisateur, mais le système ne récupère rien. C'est rageant. La commande lsof +L1 permet de lister ces fichiers fantômes. Pour libérer l'espace sans redémarrer le service, on peut parfois tronquer le fichier à zéro au lieu de le supprimer brutalement.
Le problème des fichiers creux (sparse files)
Certains fichiers annoncent une taille énorme mais ne consomment presque rien sur le disque. Ce sont des fichiers creux. On les trouve souvent dans les images de machines virtuelles. Si vous voyez un fichier de 100 Go sur un disque de 80 Go, ne paniquez pas. Utilisez ls -ls pour voir la taille réelle allouée physiquement sur les blocs du disque.
Les liens physiques et symboliques
Compter deux fois la même donnée est une erreur fréquente. Les liens physiques pointent vers le même inode. Si vous ne faites pas attention, vos outils de mesure pourraient vous faire croire que vous avez deux fichiers massifs alors qu'il n'y en a qu'un seul. La plupart des outils modernes comme du gèrent cela intelligemment, mais il faut rester vigilant lors de l'utilisation de scripts personnalisés.
Nettoyage efficace après la détection
Trouver c'est bien, agir c'est mieux. Pour les logs, privilégiez la rotation. Le service logrotate est là pour ça. Il compresse les vieux fichiers et supprime les plus anciens selon vos règles. C'est propre. Pour les paquets, un sudo apt clean fait souvent des miracles sur les systèmes basés sur Debian.
Vider les caches utilisateur
Sur votre bureau Linux, regardez du côté de ~/.cache. C'est souvent un champ de ruines. Des miniatures d'images par milliers, des résidus de sessions passées. On peut tout vider sans risque majeur, le système recréera ce dont il a besoin. C'est une méthode radicale mais efficace pour regagner quelques gigaoctets rapidement.
Analyser les bases de données
Si vous hébergez un serveur MySQL ou PostgreSQL, les fichiers de données peuvent grossir indéfiniment. Un simple find vous montrera les gros fichiers .ibd ou .dat. Mais attention, on ne supprime jamais ces fichiers à la main. Il faut passer par des commandes SQL de type OPTIMIZE TABLE ou VACUUM. C'est plus sûr.
Maintenance sur le long terme
Une bonne hygiène système demande de la régularité. Ne laissez pas la poussière numérique s'accumuler. Fixez-vous une règle : si vous ne savez pas ce qu'est un fichier de 2 Go, il n'a probablement rien à faire sur votre racine. Déplacez-le sur un stockage externe ou supprimez-le.
Utiliser des partitions séparées
C'est une vieille pratique qui reste pertinente. Mettre /home ou /var sur des partitions distinctes évite qu'un débordement de logs ne bloque le démarrage du système. Si /var est plein, le système peut encore booter. C'est un filet de sécurité structurel.
Monitorer avec des alertes
Des outils comme Zabbix ou Prometheus permettent de suivre l'évolution de l'occupation disque. Voir une courbe monter progressivement est plus instructif qu'un constat brutal de saturation. On anticipe. On planifie l'extension du stockage ou le nettoyage bien avant l'urgence.
Étapes pratiques pour reprendre le contrôle de votre disque
Pour finir, voici la marche à suivre exacte pour nettoyer votre système dès maintenant. Suivez ces étapes dans l'ordre pour un résultat optimal.
- Identifiez les points de montage les plus chargés avec la commande
df -h. Regardez la colonne "Utilisation %". Focalisez-vous sur les partitions dépassant 80 %. - Lancez une recherche globale sur les fichiers de plus de 100 Mo. Utilisez la commande suivante :
sudo find / -type f -size +100M -exec ls -lh {} + | awk '{ print $5 ": " $9 }' | sort -h. Cela vous donnera une liste claire et classée. - Vérifiez l'état de vos journaux système. La commande
journalctl --disk-usagevous dira combien de place prennent les logs de systemd. Si c'est trop, limitez la taille avecsudo journalctl --vacuum-size=500M. - Nettoyez les caches de votre gestionnaire de paquets. Pour Ubuntu ou Debian, lancez
sudo apt-get clean. Pour Fedora ou CentOS, utilisezsudo dnf clean all. - Installez Ncdu avec
sudo apt install ncdu(ou votre gestionnaire habituel) et lancez-le sur la racine avecsudo ncdu /. Parcourez les dossiers pour repérer les accumulations anormales dans les répertoires utilisateurs ou les dossiers d'application. - Vérifiez les processus qui retiennent des fichiers supprimés. Tapez
sudo lsof / | grep deleted. Si vous voyez de gros fichiers dans cette liste, redémarrez les services concernés pour libérer l'espace réel sur le disque. - Pour les utilisateurs de Docker, faites le ménage avec
docker system prune -a. Attention, cela supprimera toutes les images non utilisées par au moins un conteneur actif. Soyez sûr de ce que vous faites. - Une fois le nettoyage terminé, relancez
df -hpour confirmer le gain de place. Si l'espace ne correspond pas à vos calculs, vérifiez la présence de snapshots système cachés.
En appliquant ces méthodes, vous ne subirez plus jamais les ralentissements liés à un disque saturé. C'est une question de méthode et d'outils. Linux vous donne tout ce qu'il faut, il suffit de savoir quelle commande appeler au bon moment. Gardez un œil sur vos partitions, restez curieux des fichiers qui grossissent, et votre système restera rapide comme au premier jour.



