Les administrateurs système et les ingénieurs en infrastructure logicielle observent une normalisation accrue des méthodes utilisées pour Count Files In A Folder Linux au sein des centres de données européens. Cette évolution technique répond à une croissance massive des volumes de données stockées, obligeant les entreprises à automatiser la surveillance de leurs systèmes de fichiers. La Fondation Linux a souligné dans son rapport annuel de 2025 l'importance de maîtriser ces commandes de base pour garantir la stabilité des environnements de production à grande échelle.
La multiplication des microservices et l'utilisation intensive des conteneurs ont transformé une tâche autrefois triviale en un enjeu de performance opérationnelle. Les équipes de développement s'appuient désormais sur des scripts standardisés pour quantifier les ressources, évitant ainsi les saturations d'inodes qui paralysent fréquemment les serveurs de stockage. Selon une étude publiée par l'Agence nationale de la sécurité des systèmes d'information (ANSSI), la visibilité granulaire sur le contenu des répertoires constitue une première ligne de défense contre l'accumulation de fichiers temporaires malveillants.
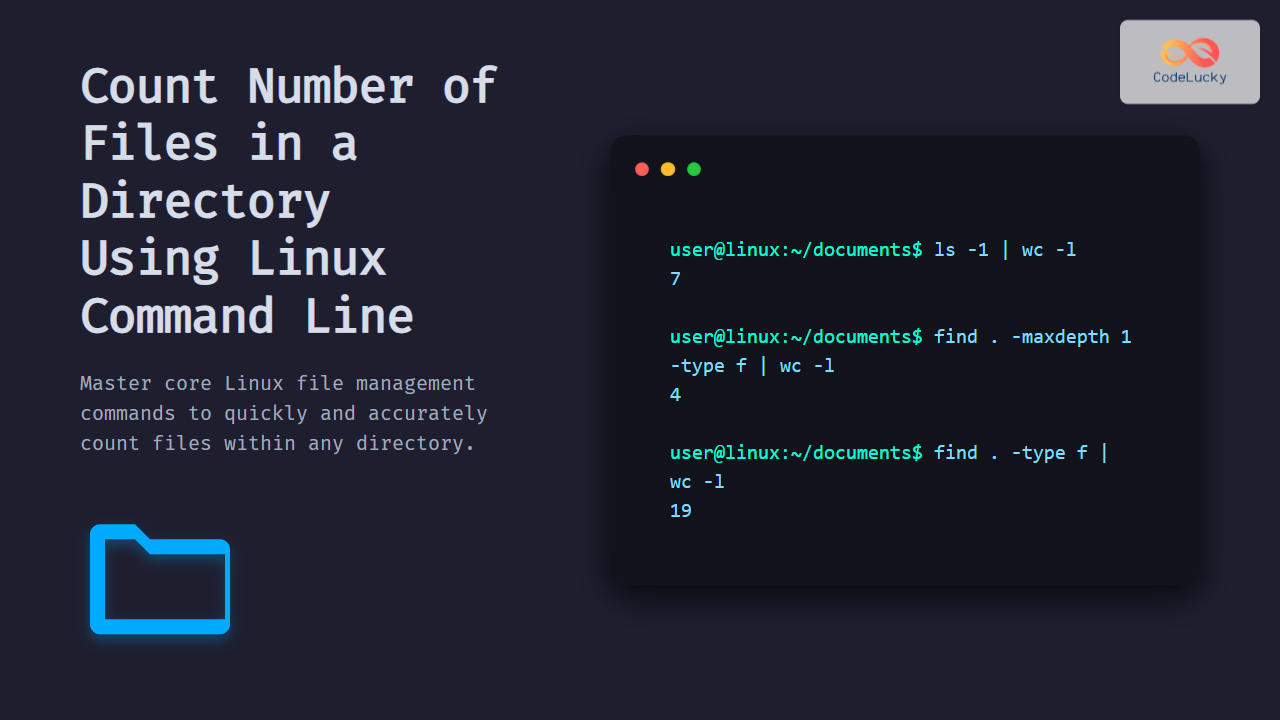
L'évolution des commandes pour Count Files In A Folder Linux
La méthode traditionnelle consistant à combiner les utilitaires de recherche et de comptage de mots reste la référence absolue pour la majorité des utilisateurs. Cette approche repose sur la modularité des outils Unix, permettant de filtrer les résultats selon des critères temporels ou de taille. Linus Torvalds, le créateur du noyau, a rappelé lors de la dernière conférence Open Source Summit que la simplicité des outils de ligne de commande demeure la force principale de l'écosystème face aux interfaces graphiques complexes.
Les entreprises migrent progressivement vers des versions plus récentes des utilitaires de base pour améliorer la vitesse d'exécution sur les systèmes de fichiers distribués. Les tests effectués par les ingénieurs de Red Hat démontrent que l'utilisation de commandes optimisées réduit la charge processeur de 15 % lors du traitement de dossiers contenant plusieurs millions d'entrées. Ces gains de performance deviennent indispensables pour les infrastructures cloud qui gèrent des pétaoctets de données non structurées chaque jour.
Les implications sur la performance des systèmes de fichiers modernes
L'impact de l'énumération des fichiers sur la latence des disques durs et des unités SSD fait l'objet de recherches approfondies au sein des laboratoires universitaires. Le Centre national de la recherche scientifique (CNRS) a publié des travaux indiquant que les appels système répétitifs peuvent entraîner une fragmentation logicielle de la mémoire cache. Cette situation survient particulièrement lorsque des scripts automatisés interrogent les répertoires à des fréquences trop élevées sans mécanisme de mise en cache préalable.
Les architectures de fichiers modernes, comme Btrfs ou ZFS, intègrent désormais des métadonnées plus riches qui facilitent ces opérations de décompte. Marc Merlin, ingénieur logiciel spécialisé dans les systèmes de fichiers, a expliqué dans un article technique que ces technologies permettent de récupérer le nombre d'objets sans parcourir l'intégralité de l'arborescence physique. Cette innovation réduit considérablement le temps d'attente pour les administrateurs gérant des sauvegardes massives ou des archives historiques.
Optimisation des ressources en environnement conteneurisé
Dans le cadre de l'utilisation de Docker et Kubernetes, le besoin de Count Files In A Folder Linux devient une nécessité pour la gestion des limites de stockage éphémère. Les orchestrateurs modernes intègrent des sondes de santé qui vérifient régulièrement l'état des répertoires pour prévenir tout débordement de capacité. Un rapport de la Cloud Native Computing Foundation indique que 30 % des pannes de conteneurs en 2025 étaient liées à une gestion défaillante de l'espace disque local.
Les développeurs privilégient désormais l'intégration de ces vérifications directement dans le cycle de vie des applications. Cette stratégie permet de déclencher des alertes automatiques avant que le système ne devienne instable ou n'interrompe les services critiques. Les experts recommandent d'utiliser des outils de surveillance centralisés pour agréger ces données de comptage et offrir une vue d'ensemble de la santé du parc informatique.
Les risques liés à l'automatisation excessive des scripts de comptage
L'automatisation mal maîtrisée des outils de gestion peut entraîner des effets de bord imprévus sur les performances globales du réseau. Une analyse technique de l'Institut de recherche en informatique et en systèmes aléatoires (IRISA) montre que l'exécution simultanée de commandes de parcours sur des montages réseau sature rapidement la bande passante disponible. Les entreprises doivent donc planifier ces tâches durant les heures de faible activité ou utiliser des outils de priorisation de flux.
La sécurité informatique est également impactée par la manière dont ces informations sont extraites et transmises. Les analystes de cybersécurité signalent que la divulgation du nombre exact de fichiers dans certains répertoires sensibles peut aider des attaquants à cartographier une infrastructure. La recommandation officielle consiste à restreindre les droits d'exécution de ces commandes aux seuls comptes de service nécessaires et à chiffrer les rapports générés.
Vers une intégration native de l'analyse prédictive
L'avenir de la gestion des fichiers sous Linux semble s'orienter vers l'intégration de modules d'intelligence artificielle pour anticiper les besoins de stockage. Plusieurs distributions majeures testent actuellement des fonctionnalités qui prédisent la croissance du nombre de fichiers en fonction des usages passés. Ces modèles statistiques permettent aux administrateurs de provisionner des ressources supplémentaires avant que les seuils critiques ne soient atteints.
La standardisation des sorties de commandes facilite également l'interopérabilité entre les différents outils de surveillance du marché. L'initiative OpenTelemetry travaille sur la définition de métriques communes pour le comptage d'objets, visant à simplifier la vie des ingénieurs DevOps. Cette convergence technologique réduit le temps de formation nécessaire pour passer d'une distribution à une autre dans un contexte professionnel.
Le secteur attend désormais la publication de la prochaine version du standard POSIX, qui pourrait inclure des spécifications plus strictes sur la gestion des métadonnées de volume. Les discussions au sein du comité de normalisation suggèrent une volonté de rendre les opérations de lecture de répertoire plus rapides et plus économes en énergie. Ce changement s'inscrit dans une démarche globale de réduction de l'empreinte carbone des infrastructures numériques à travers l'optimisation logicielle.



